感谢 whitefucloud(微信ID)整理笔记前言
这个教程是一棵树zj(https://github.com/yikeshu0611)
演示的爬虫笔记
爬取科学网,网址为:
http://fund.sciencenet.cn/search/smallSubject?subject=H0101&yearStart=2018&yearEnd=2018&submit=list
内容如下所示:
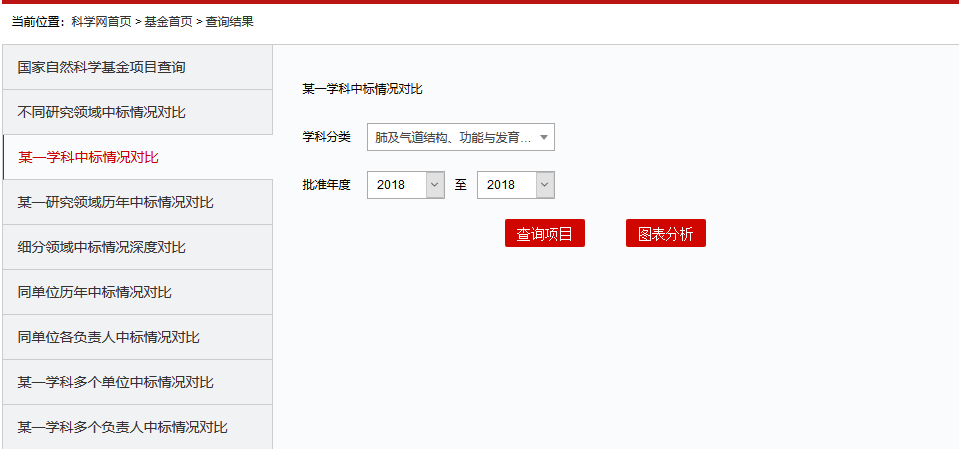
爬虫的思路就是:
读取网页;
提取数据。
R包使用rvest包中的read_html()函数提取网页中的内容。
读取国自然操作1. 读取网页安装并加载rvest包;
将网址赋值给url;
使用read_html()函数读取,如下所示:
install.packages("rvest")
library(rvest)
url='http://fund.sciencenet.cn/search/smallSubject?subject=H0101&yearStart=2018&yearEnd=2018&submit=list'
read_html(url)
结果如下所示:
> read_html(url)
{html_document}
<html xmlns="http://www.w3.org/1999/xhtml">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" ...
[2] <body>\n <div id="hd">\n <div class="wp">\n <ifra ...
上面的结果就是网页结构,其中<head>是网页的头部,<body>是网页的主体。
2. 读取数据读取数据则是要定位从哪里开始读取,还是先回到网页部分,如下所示:
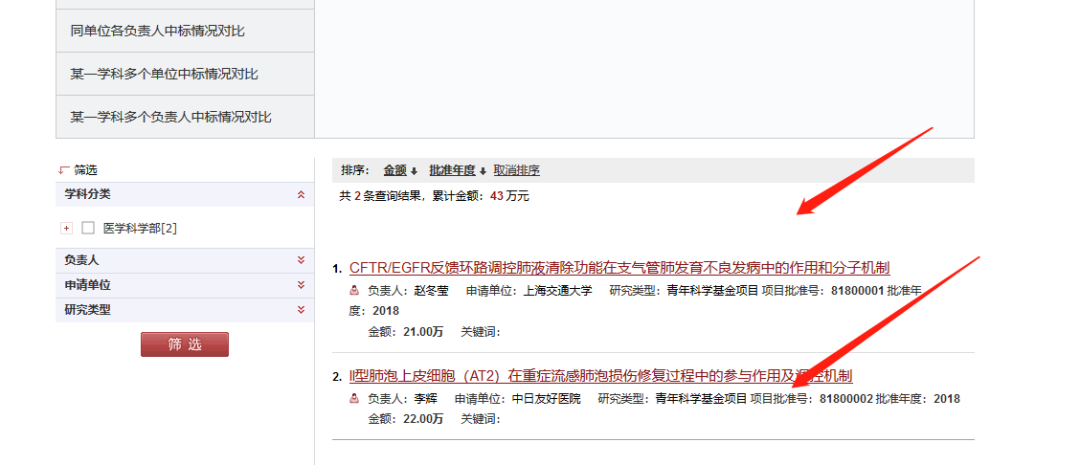
把鼠标放到上面的题目上,然后单击右键,选择审查元素(chrome浏览器),如下所示:

在上面网址那一行单击右键,复制->Xpath,如下所示:
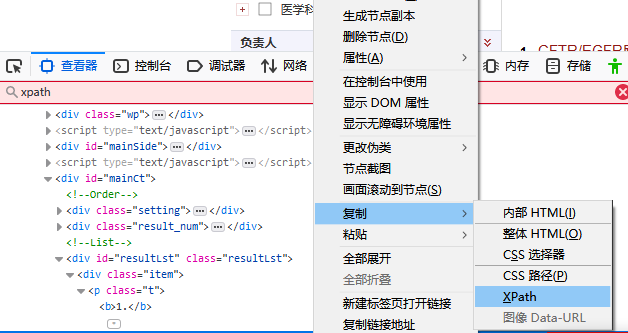
复制的内容是
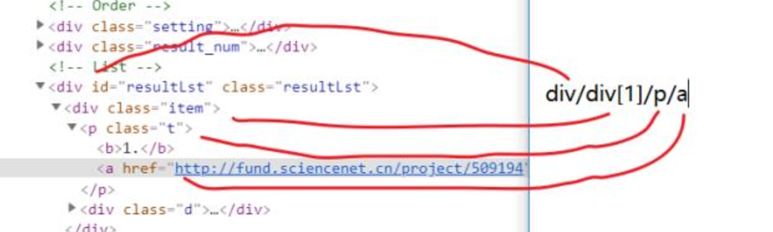
//*[@id="resultLst"]/div[1]/p/a。
现在复制另外一个题目的xpath,内容为
//*[@id="resultLst"]/div[2]/p/a。
从这两个内容上我们可以大概知道,
id="resultLst"对应了<div id="resultLst"--------</div>,
如下所示:

在上面的html代码中,我们哦可以发现,这一部分有2个div,第一个题目是div[1],第2个题目是div[2],依次类推,最后一个就是div[last()](不要过于纠结这种写法)。
现在我们看第1个div,div下面是p节点,如下所示:
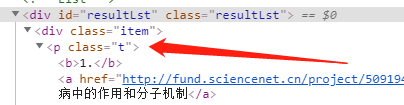
p节点下面又有2个节点,b和a,b节点那里是1,就是项目前面的标号,如下所示:

a节点下面是href="...",如下所示:

我们可以看到,在a节点现在有2个内容,第1个是链接,第2个是文本,也就是标题,我们的目标就是这个项目标题,现在我们从div那个节点开始,来写这个标题的地址,这个网址的结果如下所示:
在rvest包中,网页的定位是使用html_nodes()函数,现在我们定位第1个标题的位置,现在将读取的网页赋值给content,来定位网页中的某个东西,例如标题1,如下所示:
content <- read_html(url)
html_nodes(x = content, xpath = '//*[@id="resultLst"]/div[1]/p/a')
结果如下所示:
> content <- read_html(url)
>
> html_nodes(x = content, xpath = '//*[@id="resultLst"]/div[1]/p/a')
{xml_nodeset (1)}
[1] <a href="http://fund.sciencenet.cn/project/50 ...
标题的xpath地址赋值给xpath,上面的结果就是相应的内容,里面就是一个文本,我们使用html_text()函数来提取这些内容,并将定位的内容赋值给location,然后再提取,如下所示:
location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]/div[1]/p/a')
html_text(location)
结果如下所示:
> location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]/div[1]/p/a')
> html_text(location)
[1] "CFTR/EGFR反馈环路调控肺液清除功能在支气管肺发育不良发病中的作用和分子机制"
现在我们提取第2个标题,如下所示:
location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]/div[2]/p/a')
html_text(location)
运行结果如下所示:
> location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]/div[2]/p/a')
> html_text(location)
[1] "II型肺泡上皮细胞(AT2)在重症流感肺泡损伤修复过程中的参与作用及调控机制"
其中改变的就是div[2]这个参数。如果是要提取最后1个题目,就是div[last()],如下所示:
> location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]/div[last()]/p/a')
> html_text(location)
[1] "II型肺泡上皮细胞(AT2)在重症流感肺泡损伤修复过程中的参与作用及调控机制"
如果是100个题目,不能这么干,我们需要把div[1]这类字符串删掉,如下所示:
> location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]//p/a')
> html_text(location)
[1] "CFTR/EGFR反馈环路调控肺液清除功能在支气管肺发育不良发病中的作用和分子机制"
[2] "II型肺泡上皮细胞(AT2)在重症流感肺泡损伤修复过程中的参与作用及调控机制"
现在就提取了所有的题目。
第二个任务:提取姓名。
现在我们再来提取作者的姓名,例如赵冬莹,前面的xpath操作和前面的相同,即//*[@id="resultLst"]/div[1]/div/p[1]/span[1]/i,现在再来复制第2个名字,即//*[@id="resultLst"]/div[2]/div/p[1]/span[1]/i,复制2个名字主要是为了找到规律。现在我们把div[1]删掉,如下所示:
location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]//div/p[1]/span[1]/i')
html_text(location)
运行结果如下所示:
> location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]//div/p[1]/span[1]/i')
> html_text(location)
[1] "赵冬莹" "李辉"
第三个任务:提取标题部分的网址,这个网址,就是标题后面链接的网址,有时候,我们需要爬取二级页面,就地需要获得二级页面的网址,我们看到这个网址不是文本,它虽然和标题在同一个位置,都是a节点下面,但是我们使用html_text()命令并没有将其提取出现,因为这个函数认为它不是文本,而是链接,对应的是herf="----------------"这种格式,如下所示:

现在我们要提取某一个具体的网页(html)属性(attribute)内容,此时我们使用html_attr()命令,例如我们要提取超链接,就写成html_attr("href"),所以,如果我们要提取标题处的链接,就需要先定位到标题那里,然后使用html_attr()函数,如下所示:
location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]//p/a')
html_attr(location, name = 'href')
结果如下所示:
> location <- html_nodes(x = content, xpath = '//*[@id="resultLst"]//p/a')
> html_attr(location, name = 'href')
[1] "http://fund.sciencenet.cn/project/509194"
[2] "http://fund.sciencenet.cn/project/509195"
读取Pubmed现在来讲一下大致思路:第一,找到网址;第二,定位,也就是说从哪个地方开始抓取数据;第三步,抓取数据。
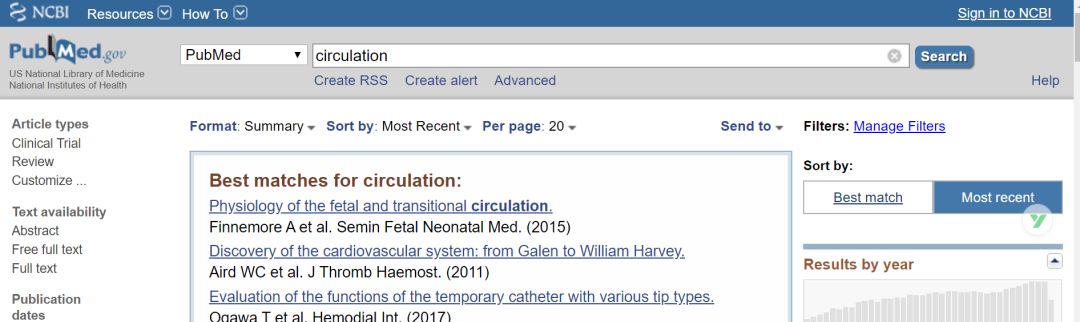
打开pubmed,https://www.ncbi.nlm.nih.gov/pubmed,输入circulation,点击搜索如下所示:
加载rvest包,输入目标网址,如下所示:
## Crawl pubmed
## Setup 1
page_content <- read_html(x = 'https://www.ncbi.nlm.nih.gov/pubmed/?term=circulation')
像前面一样,右键xpath,如下所示:

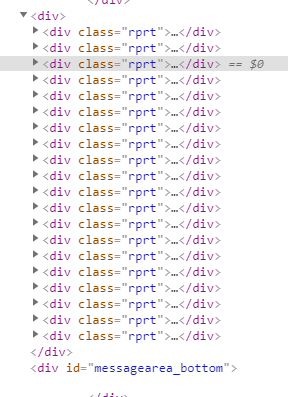
其中,一个rprt对应的就是左侧的蓝色阴影部分,一共有20个这样的结构(其实就是一页中的20个结果),如下所示:
我们再回到第1个题目,右键,copy xpath,如下所示:
## Crawl pubmed
## Setup 1
page_content <- read_html(x = 'https://www.ncbi.nlm.nih.gov/pubmed/?term=circulation')
## Step 2: Crawl content
#xpath
node = '//*[@id="maincontent"]/div/div[5]/div[1]/div[2]/p/a'
html_nodes(x = page_content, xpath = node)
结果如下所示:
> html_nodes(x = page_content, xpath = node)
{xml_nodeset (1)}
[1] <a href="/pubmed/31603578" ref="ordinalpos=1&ncbi_uid=31603578&link_ ...
读取上面内容中的文本部分,如下所示:
## Step 2: Crawl content
#xpath
### 2.1 Location
node = '//*[@id="maincontent"]/div/div[5]/div[1]/div[2]/p/a'
nodes_content <- html_nodes(x = page_content, xpath = node)
### 2.2 Crawl data
html_text(x = nodes_content, trim = T)
现在我们提取第2个题目的xpath,再将它与第1个比较,如下所示:
//*[@id="maincontent"]/div/div[5]/div[1]/div[2]/p/a
//*[@id="maincontent"]/div/div[5]/div[2]/div[2]/p/a
我们可以找到它们的共同规律,即//*[@id="maincontent"]/div/div[5]//div[2]/p/a,如下所示:
### 2.1 Location
node = '//*[@id="maincontent"]/div/div[5]//div[2]/p/a'
# 这里要注意//与/的区别,/表示绝对路径,//表示相对路径
nodes_content <- html_nodes(x = page_content, xpath = node)
### 2.2 Crawl data
html_text(x = nodes_content, trim = T)
运行结果如下所示:
> ### 2.1 Location
> node = '//*[@id="maincontent"]/div/div[5]//div[2]/p/a'
> nodes_content <- html_nodes(x = page_content, xpath = node)
>
> ### 2.2 Crawl data
> html_text(x = nodes_content, trim = T)
[1] "Variation of organ position in snakes."
[2] "Similar articles"
[3] "Pathogenesis of Cluster Headache: From Episodic to Chronic Form, the Role of Neurotransmitters and Neuromodulators."
[4] "Similar articles"
[5] "Haemodynamic evaluation of the new pulsatile-flow generation method in vitro."
[6] "Similar articles"
[7] "Stacking as a Key Property for Creating Nanoparticles with Tunable Shape: The Case of Squalenoyl-Doxorubicin."
[8] "Similar articles"
[9] "[Study on absorbed components of Aconitum kusnezoffii under Yunnan Baiyao compatibility in effect of activating blood circulation and removing blood stasis]."
[10] "Similar articles"
[11] "[Application of quality constant method in grade evaluation of Aurantii Fructus Immaturus pieces]."
[12] "Similar articles"
[13] "[Study on regularity of Tibetan medicine in treatment of gZav-Grib disease (apoplexy sequelae) based on HIS clinical medical records]."
[14] "Similar articles"
[15] "Exercise responses in children and adults with a Fontan circulation at simulated altitude."
[16] "Similar articles"
[17] "The Course of Immune Stimulation by Photodynamic Therapy: Bridging fundamentals of photochemically-induced Immunogenic Cell Death to the Enrichment of T Cell Repertoire."
[18] "Similar articles"
[19] "Design of Dense Brush Conformation Bearing Gold Nanoparticles as Theranostic Agent for Cancer."
[20] "Similar articles"
[21] "Liquid biopsy: one cell at a time."
[22] "Similar articles"
[23] "The Evolving Role of Neutrophils in Liver Transplant Ischemia-Reperfusion Injury."
[24] "Similar articles"
[25] "Predictors of Balloon Guide Catheter Assistance Success in Stent-retrieval Thrombectomy for an Anterior Circulation Acute Ischemic Stroke."
[26] "Similar articles"
[27] "High mobility group box protein 1 neutralization therapy in ovine bacteremia: Lessons learned from an ovine septic shock model incorporating intensive care support."
[28] "Similar articles"
[29] "Low human and murine Mcl-1 expression leads to a pro-apoptotic plaque phenotype enriched in giant-cells."
[30] "Similar articles"
[31] "Upper-tropospheric bridging of wintertime surface climate variability in the Euro-Atlantic region and northern Asia."
[32] "Similar articles"
[33] "Discordances between predicted and actual risk in obese patients with suspected cardiac ischaemia."
[34] "Similar articles"
[35] "Tumor-Associated Release of Prostatic Cells into the Blood after Transrectal Ultrasound-Guided Biopsy in Patients with Histologically Confirmed Prostate Cancer."
[36] "Similar articles"
[37] "Circulating tumor cells exhibit metastatic tropism and reveal brain metastasis drivers."
[38] "Similar articles"
[39] "Permanent pacing post-Fontan is not associated with reduced long-term survival."
[40] "Similar articles"
一共有40个结果,里面有相同的字符串,即"Similar articles",这个不是我们需要的,这因为定位出现了问题,也就是说node = '//*[@id="maincontent"]/div/div[5]//div[2]/p/a'这段代码有问题,现在我们查看原题目与Similar articles的元素,如下所示:
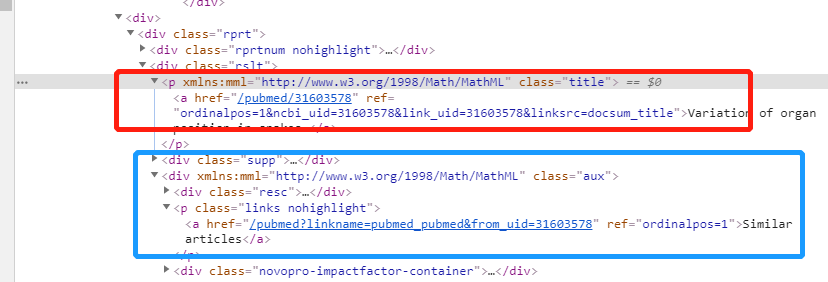
其中,红框是我们要爬取的题目,而蓝框则similar articles的内容,因此我们需要把蓝框的内容给剔掉,只爬取到class="title"这个字段就行,也就是说添加上p[@class="title"],如下所示:
### 2.1 Location
node = '//*[@id="maincontent"]/div/div[5]//div[2]/p[@class="title"]/a'
# 这里要注意//与/的区别,/表示绝对路径,//表示相对路径
nodes_content <- html_nodes(x = page_content, xpath = node)
### 2.2 Crawl data
html_text(x = nodes_content, trim = T)
结果如下所示:
> ### 2.1 Location
> node = '//*[@id="maincontent"]/div/div[5]//div[2]/p[@class="title"]/a'
> # 这里要注意//与/的区别,/表示绝对路径,//表示相对路径
>
> nodes_content <- html_nodes(x = page_content, xpath = node)
>
> ### 2.2 Crawl data
> html_text(x = nodes_content, trim = T)
[1] "Variation of organ position in snakes."
[2] "Pathogenesis of Cluster Headache: From Episodic to Chronic Form, the Role of Neurotransmitters and Neuromodulators."
[3] "Haemodynamic evaluation of the new pulsatile-flow generation method in vitro."
[4] "Stacking as a Key Property for Creating Nanoparticles with Tunable Shape: The Case of Squalenoyl-Doxorubicin."
[5] "[Study on absorbed components of Aconitum kusnezoffii under Yunnan Baiyao compatibility in effect of activating blood circulation and removing blood stasis]."
[6] "[Application of quality constant method in grade evaluation of Aurantii Fructus Immaturus pieces]."
[7] "[Study on regularity of Tibetan medicine in treatment of gZav-Grib disease (apoplexy sequelae) based on HIS clinical medical records]."
[8] "Exercise responses in children and adults with a Fontan circulation at simulated altitude."
[9] "The Course of Immune Stimulation by Photodynamic Therapy: Bridging fundamentals of photochemically-induced Immunogenic Cell Death to the Enrichment of T Cell Repertoire."
[10] "Design of Dense Brush Conformation Bearing Gold Nanoparticles as Theranostic Agent for Cancer."
[11] "Liquid biopsy: one cell at a time."
[12] "The Evolving Role of Neutrophils in Liver Transplant Ischemia-Reperfusion Injury."
[13] "Predictors of Balloon Guide Catheter Assistance Success in Stent-retrieval Thrombectomy for an Anterior Circulation Acute Ischemic Stroke."
[14] "High mobility group box protein 1 neutralization therapy in ovine bacteremia: Lessons learned from an ovine septic shock model incorporating intensive care support."
[15] "Low human and murine Mcl-1 expression leads to a pro-apoptotic plaque phenotype enriched in giant-cells."
[16] "Upper-tropospheric bridging of wintertime surface climate variability in the Euro-Atlantic region and northern Asia."
[17] "Discordances between predicted and actual risk in obese patients with suspected cardiac ischaemia."
[18] "Tumor-Associated Release of Prostatic Cells into the Blood after Transrectal Ultrasound-Guided Biopsy in Patients with Histologically Confirmed Prostate Cancer."
[19] "Circulating tumor cells exhibit metastatic tropism and reveal brain metastasis drivers."
[20] "Permanent pacing post-Fontan is not associated with reduced long-term survival."
此时,如果想读取链接,则如下所示:
### 2.1 Location
node = '//*[@id="maincontent"]/div/div[5]//div[2]/p/a'
# 这里要注意//与/的区别,/表示绝对路径,//表示相对路径
nodes_content <- html_nodes(x = page_content, xpath = node)
### 2.2 Crawl data
html_attr(x = nodes_content, name = "href")
结果如下所示:
> html_attr(x = nodes_content, name = "href")
[1] "/pubmed/31603578" "/pubmed?linkname=pubmed_pubmed&from_uid=31603578"
[3] "/pubmed/31603552" "/pubmed?linkname=pubmed_pubmed&from_uid=31603552"
[5] "/pubmed/31603372" "/pubmed?linkname=pubmed_pubmed&from_uid=31603372"
[7] "/pubmed/31603305" "/pubmed?linkname=pubmed_pubmed&from_uid=31603305"
[9] "/pubmed/31602894" "/pubmed?linkname=pubmed_pubmed&from_uid=31602894"
[11] "/pubmed/31602882" "/pubmed?linkname=pubmed_pubmed&from_uid=31602882"
[13] "/pubmed/31602864" "/pubmed?linkname=pubmed_pubmed&from_uid=31602864"
[15] "/pubmed/31602790" "/pubmed?linkname=pubmed_pubmed&from_uid=31602790"
[17] "/pubmed/31602649" "/pubmed?linkname=pubmed_pubmed&from_uid=31602649"
[19] "/pubmed/31602558" "/pubmed?linkname=pubmed_pubmed&from_uid=31602558"
[21] "/pubmed/31602399" "/pubmed?linkname=pubmed_pubmed&from_uid=31602399"
[23] "/pubmed/31602356" "/pubmed?linkname=pubmed_pubmed&from_uid=31602356"
[25] "/pubmed/31602354" "/pubmed?linkname=pubmed_pubmed&from_uid=31602354"
[27] "/pubmed/31602200" "/pubmed?linkname=pubmed_pubmed&from_uid=31602200"
[29] "/pubmed/31601924" "/pubmed?linkname=pubmed_pubmed&from_uid=31601924"
[31] "/pubmed/31601851" "/pubmed?linkname=pubmed_pubmed&from_uid=31601851"
[33] "/pubmed/31601728" "/pubmed?linkname=pubmed_pubmed&from_uid=31601728"
[35] "/pubmed/31601564" "/pubmed?linkname=pubmed_pubmed&from_uid=31601564"
[37] "/pubmed/31601552" "/pubmed?linkname=pubmed_pubmed&from_uid=31601552"
[39] "/pubmed/31601284" "/pubmed?linkname=pubmed_pubmed&from_uid=31601284"
此时读取了40项内容,又多了一倍,还是跟前面的问题一样,此时需要过滤一下(核心内容就是正则表达式),如下所示:
### 2.1 Location
node = '//div[@class="rprt"]/div[@class="rslt"]/p[@class="title"]/a'
# 这里要注意//与/的区别,/表示绝对路径,//表示相对路径
nodes_content <- html_nodes(x = page_content, xpath = node)
### 2.2 Crawl data
html_attr(x = nodes_content, name = "href")
结果如下所示:
> html_attr(x = nodes_content, name = "href")
[1] "/pubmed/31603578" "/pubmed/31603552" "/pubmed/31603372" "/pubmed/31603305" "/pubmed/31602894" "/pubmed/31602882"
[7] "/pubmed/31602864" "/pubmed/31602790" "/pubmed/31602649" "/pubmed/31602558" "/pubmed/31602399" "/pubmed/31602356"
[13] "/pubmed/31602354" "/pubmed/31602200" "/pubmed/31601924" "/pubmed/31601851" "/pubmed/31601728" "/pubmed/31601564"
[19] "/pubmed/31601552" "/pubmed/31601284"
其实我们可以发现,node = '//div[@class="rprt"]/div[@class="rslt"]/p[@class="title"]/a'这一句中的最后一部分node = '//p[@class="title"]/a'其实是唯一标记的,也就是说在这个路径中没有重复,因此我们还可以改一下代码,把这个字符前面的都删掉,如下所示:
### 2.1 Location
node = '//p[@class="title"]/a'
# 这里要注意//与/的区别,/表示绝对路径,//表示相对路径
nodes_content <- html_nodes(x = page_content, xpath = node)
### 2.2 Crawl data
html_attr(x = nodes_content, name = "href")
运行一下,如下所示:
> ### 2.1 Location
> node = '//p[@class="title"]/a'
> # 这里要注意//与/的区别,/表示绝对路径,//表示相对路径
> nodes_content <- html_nodes(x = page_content, xpath = node)
> ### 2.2 Crawl data
> html_attr(x = nodes_content, name = "href")
[1] "/pubmed/31603578" "/pubmed/31603552" "/pubmed/31603372" "/pubmed/31603305" "/pubmed/31602894" "/pubmed/31602882"
[7] "/pubmed/31602864" "/pubmed/31602790" "/pubmed/31602649" "/pubmed/31602558" "/pubmed/31602399" "/pubmed/31602356"
[13] "/pubmed/31602354" "/pubmed/31602200" "/pubmed/31601924" "/pubmed/31601851" "/pubmed/31601728" "/pubmed/31601564"
[19] "/pubmed/31601552" "/pubmed/31601284"
结果是一样的,这里要学习的就是唯一标记符,使用这种方法非常高效(核心就是找到唯一的节点)。
简化操作之管道上面介绍的这个爬虫过程,都需要找到网址,输入节点,比较麻烦,因此可以采取管道(%>%)来简化操作,如下所示:
## pipeline operation
page_content <- read_html(x = 'https://www.ncbi.nlm.nih.gov/pubmed/?term=circulation')
# title
node <- '//p[@class="title"]/a'
page_content %>%
html_nodes(xpath = node) %>%
html_text(trim = T)
# Link
page_content %>%
html_nodes(xpath = node) %>%
html_attr(name = 'href')
简化操作之函数上面的操作还能继续简化,也就是写成一个函数,R中构建函数的内容可以找本书看看,这里直接放代码,如下所示:
## Contruction function for web site
read_html.my <- function(url){
library(rvest)
page_concent <<- read_html(x = url)
# note symbol "<<-" is transform local variable into global variable
}
read_html.my('https://www.ncbi.nlm.nih.gov/pubmed/?term=circulation')
# Read text from web site
html_text.my <- function(xpath){
page_concent %>%
html_nodes(xpath = xpath) %>%
html_text(trim = T)
}
# Read link from web site
html_href.my <- function(xpath){
page_concent %>%
html_nodes(xpath = xpath) %>%
html_attr(name = 'href')
}
html_text.my('//p[@class="title"]/a')
html_href.my('//p[@class="title"]/a')
总结涉及到的知识点大概如下所示:
网页的构成(xpath,html,css,绝对路径(/)与相对路径(//,节点,内容);
正则表达式;
R中函数的构建(局部变量,变局变量,局部变量切换为全局变量<<-);
管道操作(%>%)。
One More Thing......
小站粉丝VIP群。
上面的课程小站VIP群的日常分享,群中大神云集,不定期会分享答疑。除了答疑之外,大神还经常讨论一些热门话题,课题、文章、国自然、生信、八卦,站长有什么新的想法和关于小站工具处于开发阶段的功能也会提前放到群里。
重要的是有树神入驻,每天分享R语言使用技巧,还有自己开发的神包。当然还会授之以渔,比如教大家如何制作R并上传CRAN,如何做R语言爬虫,如何整理医院His系统的数据等等,每天都有新知识,与大家一同进步。
下面是整理的树神教程:
R高级|利用cowplot包拼接图片(1)基本操作
R语言中实现文本替换其实很简单,记住do Replace就好~文末有彩蛋
R基础|do包(3):宽型数据转长型数据reshape_toLong(1)
R基础|do包(1):左截取、右截取、中间截取
此群59元会员制,群里还有名额,如果大家感兴趣可以加站长微信,发59元红包,站长拉你入群。
入群可以获得
1、2019年生命科学部
2、2019年医学部所有中标名单
3、2017年肿瘤口中标项目摘要
4、RCheatsheets学习卡片和其他资料

彩蛋
站长收集了R语言学习卡片的PDF版本例如
R语言学习卡片









获得方式
1、分享此文到朋友圈24小时无删除或者分享此文到3个微信群(人数>300)
2、截图直接在微信公众号内回复即可。。
资料收集不易,用2000行代码写的网站工具更不易,为了宣传一个免费又强大的网站工具,麻烦大家了~


