技术改变世界,撸码改变生活
突然爱上撸码,那就继续撸....
本着在项目中学习Python的精神,上篇用Python分析了周杰伦的歌词,结果不是很理想。因为当前NLP的理论和算法并不高级,不能真实全面的分析歌词,只能做简单的分词,词频统计,TD-IDF分析和非黑即白的情感分析。
那这次就来点简单的,用Python来生成文章的自动摘要。分析什么文章呢?《证券基金经营机构信息技术管理办法 》吧,比较熟悉。
自动摘要理论
自动摘要方法最早出自1958年的IBM公司科学家H.P. Luhn的论文《The Automatic Creation of Literature Abstracts》。Luhn提出用"簇"(cluster)表示关键词的聚集。所谓"簇"就是包含多个关键词的句子片段。
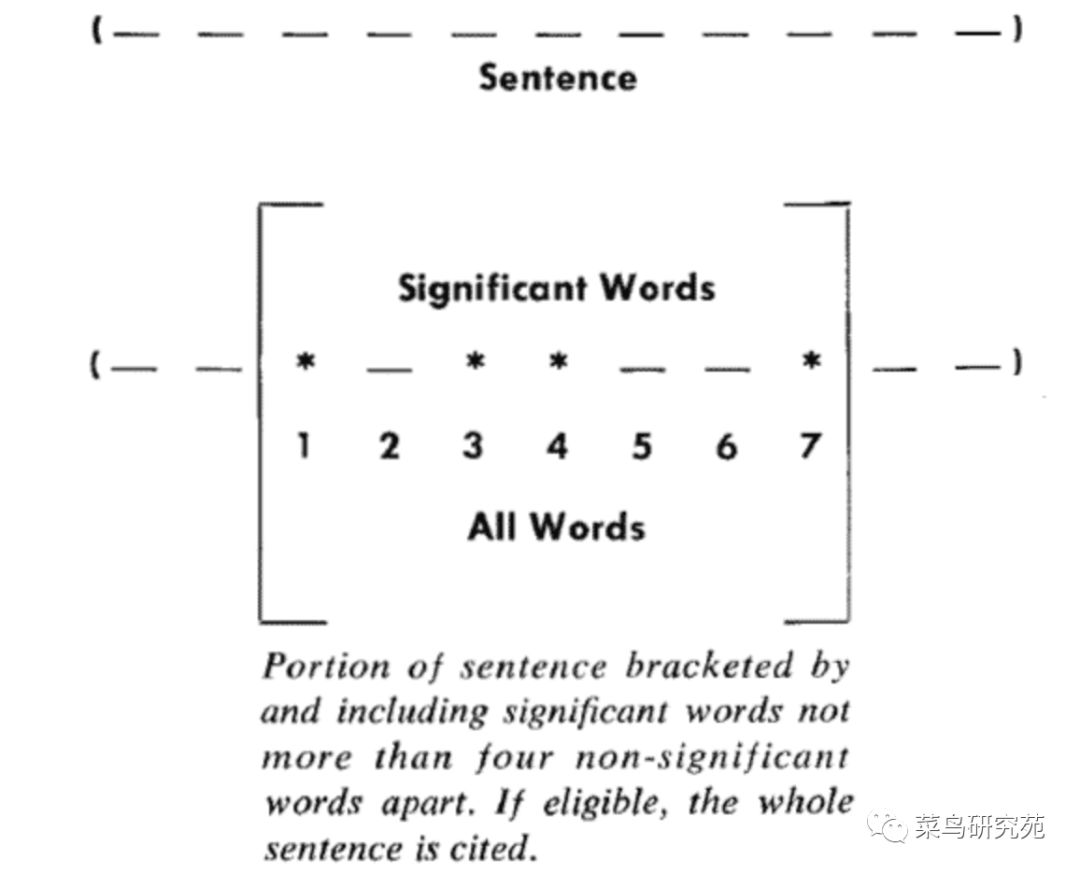
上图就是Luhn原始论文的插图,被框起来的部分就是一个"簇"。只要关键词之间的距离小于"门槛值",它们就被认为处于同一个簇之中。Luhn建议的门槛值是4或5。
簇的计算公式:簇的重要性 = 关键字个数*关键字个数/簇的长度。
小编:为了简化计算,结合法律法规文件写作特点,很少使用短句,本文将簇视为一个句子,一句即成一簇。句子重要性分值计算公式:关键字个数*关键字个数/簇的长度。
但是仅统计句子包含关键词的多少来决定句子的重要性是不是比较单一?句子,特别是中文,句子表达(通俗讲语气)也是句子重要性的一个指标。所以考虑联合簇计算和情感分析一起来判断句子的重要性。
编码流程就这样了:
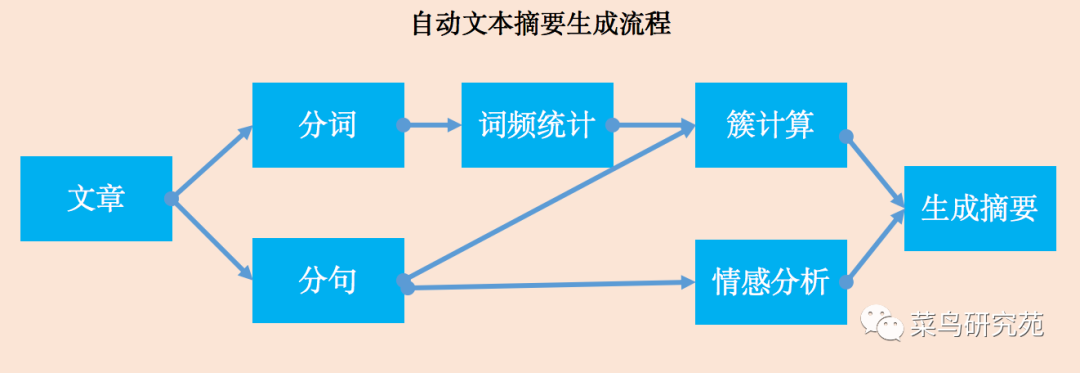
1,素材准备
因为重点是练习自动摘要,就直接在证监会官网下载PDF,然后复制粘贴成txt文件。
2,分词
复制现成的函数,稍微改改就成了。
for ci in jieba.lcut(line):
#过滤停用词,保存分词结果 if ''.join(ci) not in stopwords: words.append(ci)
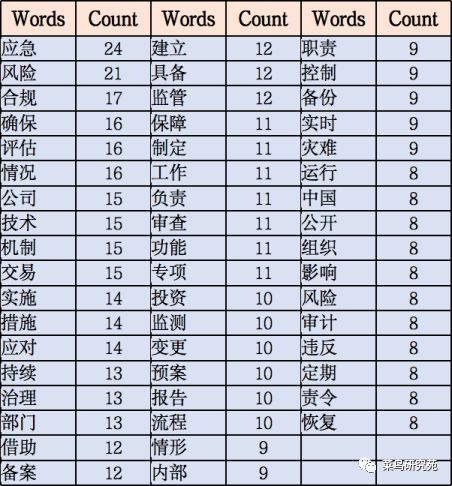
3,词频统计
利用Python的count函数实现统计功能,比自然语言处理工具包nltk方便呀。词频统计结果用字典保存然后写csv文件。csv文件可以用Excel打开,Excel的效率高呀。 #用read()将分词文件读成字符串
#调用count函数统计词语的出现次数。
words[key] = f2.read().count(key)
根据分词结果,生成的词云如下:

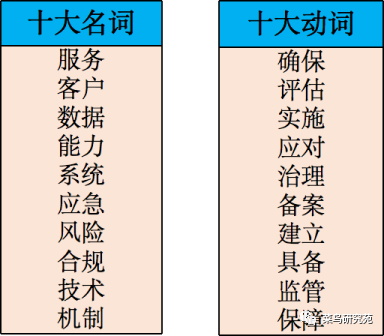
注意:因为管理办法是证监会对证券基金的信息技术管理提出的要求,所以分词结果包含大量主题词如中国证监会、机构、证券、基金、经营机构、信息、技术、管理、系统等。如果将这些主题词引入到后续的分析,那几乎全文都是关键句,生成的摘要也几乎是全文了,这样达不到分析的目的。
排名最前的十大动词和十大名,有想做连线题的冲动吗?
4,分成句子
将文档按中文标点“,。;”分成句子。用正则表达式,两行代码搞定:
f1 = open(u'管理办法.txt','r',encoding='utf-8') for i in re.split(u',|;|。|;|,',f1.read()): sen.append(i.replace(" ", "").replace("\n", ""))
5,簇计算
按照簇重要性计算公式,重点在计算句子包含的关键词个数。
#关键词和句子是列表。
#本来想直接用readlines()读取按行处理,调试半天没成功,要血命。
for i in range(len(sen)-1):
total = 0
for j in range(len(keywords)-1):
total=total+sen[i].count(keywords[j])
j+=1
if len(sen[i]) !=0:
keysen[sen[i]]=total*total/len(sen[i])
i+=1
fun_dict2File(keysen, 'score.csv')
结果得分排前十的句子:
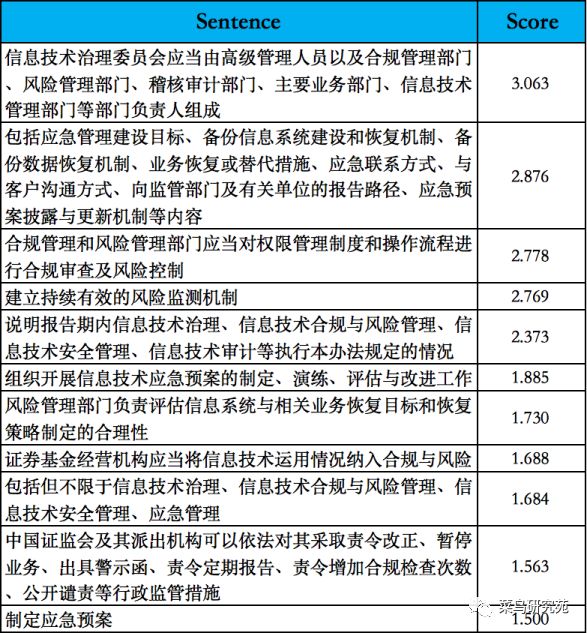
根据这十个句子,结尾加上标点,合并得到文档的摘要。将句子合并其实很复杂,涉及词性和语法分析,主谓宾定状补是否完整,如何补充?目的是让句子通顺,没语法错误。这就不多研究了,直接手工合并。

接下来我们扩大范围,全文分成句子后将近370行,这次选取排名前30的句子,再来看看这些句子的重点内容是什么?
6,情感分析
百度情感分析对免费用户的调用是有限制的,QPS=2,即每秒最多调用两次。经过测试,调用一次休眠至少0.7秒。如果休眠0.6秒,调用几十次之后就会报错。
百度接口调用前需要登录,结果返回是JSON格式,可以通过字典来截取sentiment值。这些操作已经封装成函数fun_getSentiment(str)了。for sen in fun_file2Sentences('管理办法.txt'): #调用百度情感分析接口,用字典保留结果 if len(sen)!=0:motion[sen] = fun_getSentiment(sen) time.sleep(0.7) fun_dict2File(motion,'sentimetn.csv')在簇得分排名30的句子中情感得分是0或2的结果如下:
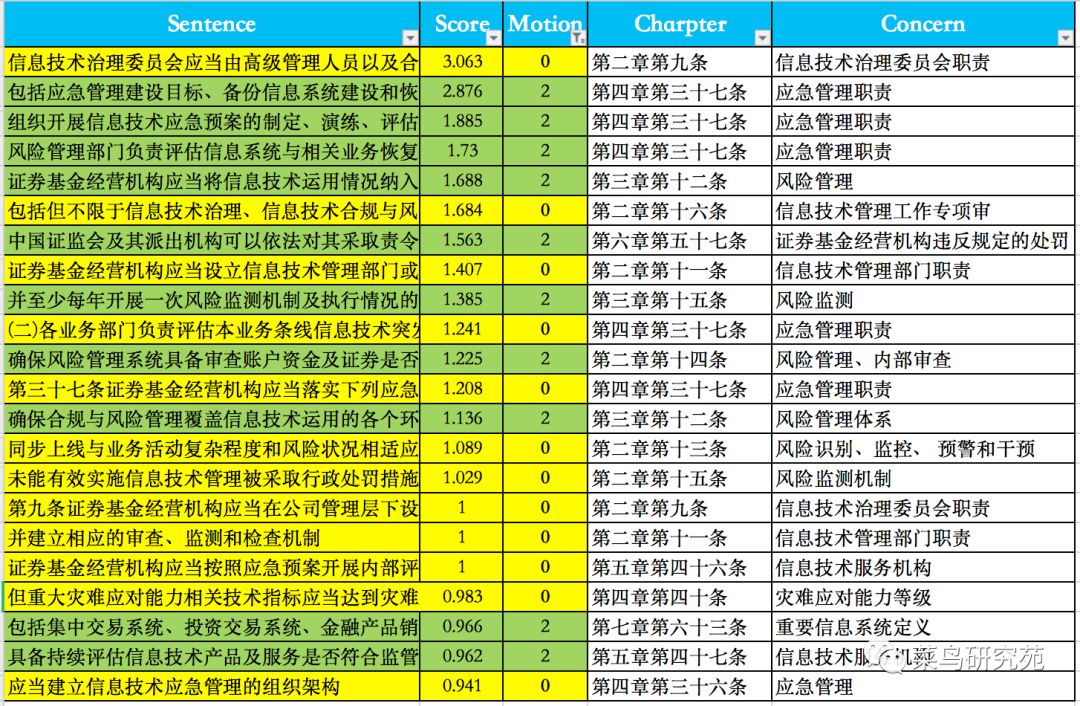
根据上表的统计,重点内容显而易见了:
1) 第四章第三节-应急管理,句子情感指数不是2就是0,是重点强调的内容。2) 第二章-信息技术治理,内容是风险管理、IT委会员和信息技术部的职责。3) 其他重点内容包括:第五章的信息技术服务机构审查和关于违反规定的处罚。 你觉得派森君和NLP先生理解的重点内容怎么样?跟你理解的一致吗?反正我是觉得这次用簇理论加情感分析来分析文章的重点内容和生成摘要挺令人满意的。核心代码不超20行,派森表现不错!
TBD.


